Online/Offline LLMs clients
Online (Librechat)
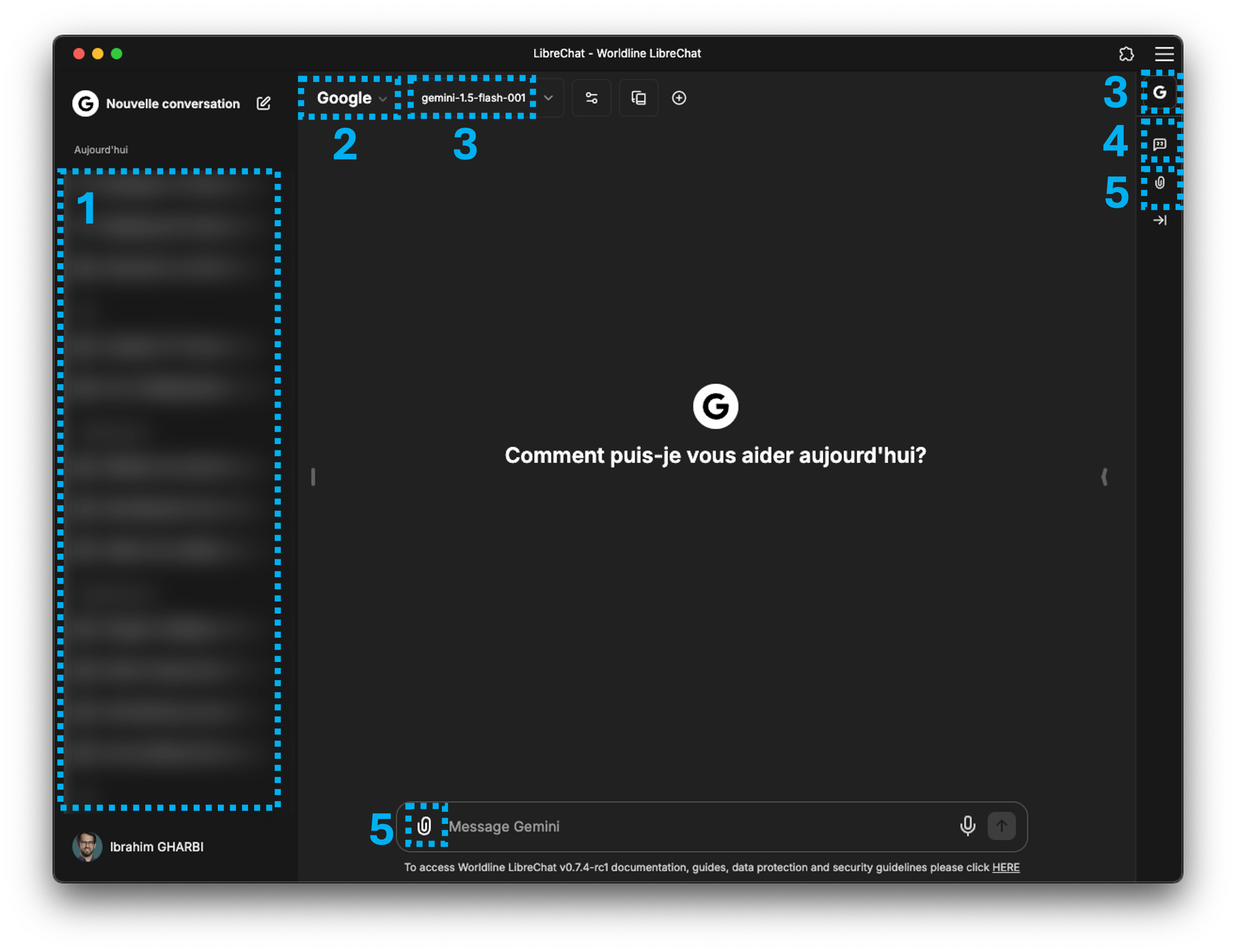
LibreChat is a free, open source AI chat platform. This Web UI offers vast customization, supporting numerous AI providers, services, and integrations. Serves all AI Conversations in one place with a familiar interface, innovative enhancements, for as many users as you need.
The full librechat documentation is available here
Let's discover how to use LibreChat to create efficient and effective conversations with AI for developers.
History
Prompts history allows users to save and load prompts for their conversations and easily access them later. Reusing prompts can save time and effort, especially when working with multiple conversations and keep track of the context and details of a conversation.
Favorites
The favorites feature allows users to save and load favorite prompts for their conversations and easily access them later.
Presets
The presets feature allows users to save and load predefined settings for initialise a conversations. Users can import and export these presets as JSON files, set a default preset, and share them with others.
Preformatted prompts
The prompts feature allows users to save and load predefined prompts to use it during their conversations. You can use a prompt with the /[prompt command]. A prompt can have parameters, which are replaced with values when the prompt is used.
Exemple of preformatted prompts : Explain the following code snippet in Java, Kotlin or Javascript
- Click on the
+button to add a new prompt. - name your prompt :
explain - on Text tab, you can write your prompt :
Explain the following {{language:Java|Kotlin|Javascript}} snippet of code:
{{code}}
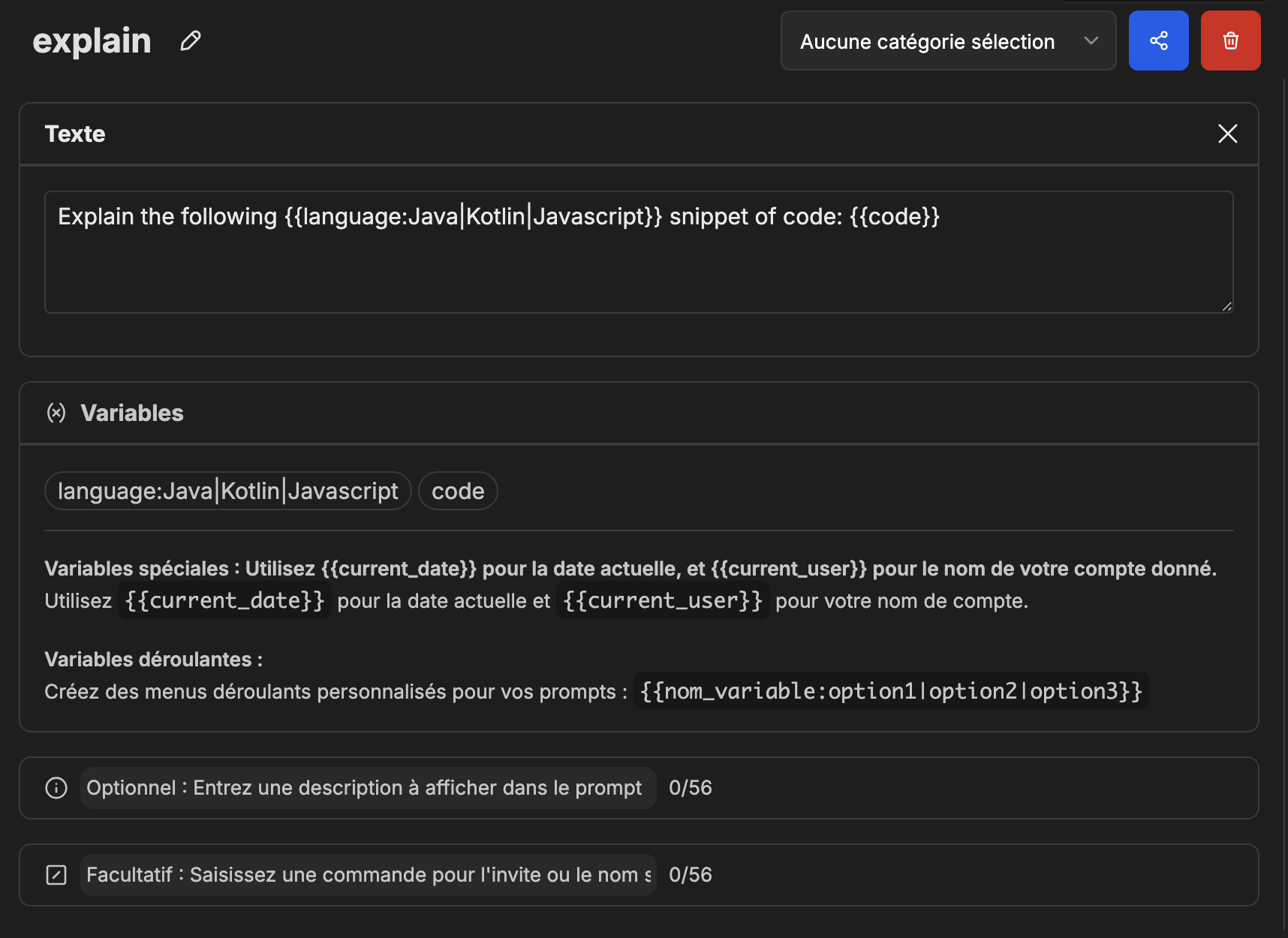
- Now you can use the
/explaincommand to get the explanation of the code snippet.
AI providers
Azure OpenAI
Azure OpenAI Service provides REST API access to OpenAI's powerful language models, including the o1-preview, o1-mini, GPT-4o, GPT-4o mini, GPT-4 Turbo with Vision, GPT-4, GPT-3.5-Turbo, and Embeddings model series.
Google Gemini
Gemini is a large language model (LLM) developed by Google. It's designed to be a multimodal AI, meaning it can work with and understand different types of information, including text, code, audio, and images. Google positions Gemini as a highly capable model for a range of tasks, from answering questions and generating creative content to problem-solving and more complex reasoning. There are different versions of Gemini, optimized for different tasks and scales.
Anthropic Claude
Claude is an Artificial Intelligence, trained by Anthropic. Claude can process large amounts of information, brainstorm ideas, generate text and code, help you understand subjects, coach you through difficult situations, help simplify your busywork so you can focus on what matters most, and so much more.
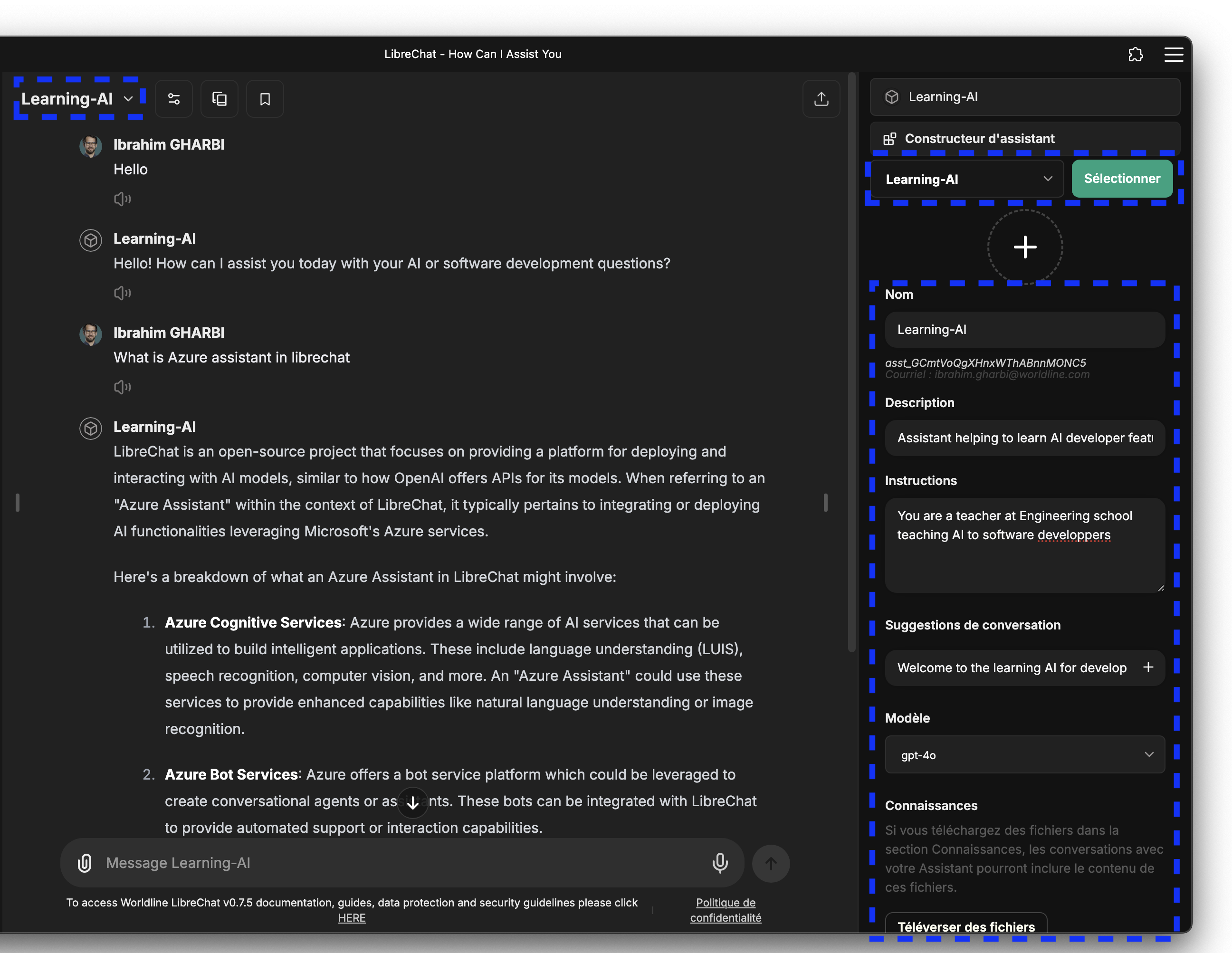
Assistants
The Assistants API enables the creation of AI assistants, offering functionalities like code interpreter, knowledge retrieval of files, and function execution. The Assistants API allows you to build AI assistants within your own applications for specific needs. An Assistant has instructions and can leverage models, tools, and files to respond to user queries. The Assistants API currently supports three types of tools: Code Interpreter, File Search, and Function calling.
Plugins
The plugins endpoint opens the door to prompting LLMs in new ways other than traditional input/output prompting.
Warning
Every additional plugin selected will increase your token usage as there are detailed instructions the LLM needs for each one For best use, be selective with plugins per message and narrow your requests as much as possible
DALL-E 3
Dall-e 3 is a librechat Plugin for generating images from text. You can use it to generate images from text, such as product descriptions, product images, or even documentation images to illustrate your technical documentation.
Confluence
Ask confluence is a librechat Plugin for Confluence documents.
IT support
Ask for IT support enable you to get support from the IT team and create WLSD tickets from your chats.
WOLF
Wolf is a librechat Plugin for WL Managagement System documents. The sharepoint documention is available here
Ask to WorldLine management system Friend everything you are looking for in the WMS content. AskWOLF plugin is meant to help you navigate through the multitude of information provided by the WMS (Applicable Policies, Processes & Procedures, Transversal & Operations SP pages links, …). This Worldline LibreChat plugin relies on ChatGPT technologies.
Worldline Management System (WMS) is the Group reference for all information pertaining to our operating model such as applicable policies, processes and governance structures. Key responsibilities are :
- consistently address its customers’ and markets’ requirements across all its geographies
- continuous improvement of customer satisfaction through effective application of WMS
- correct interpretation of applicable ISO standards requirements
Example of prompts:
- AskWOLF: What is the WMS?
- AskWOLF: What are the policies?
- AskWOLF: What are the processes?
Browse plugins
Retrieve data from internet and use it to generate a response.
Plugin mixing
You can mix plugins to create more complex prompts. For example, you can use the DALL-E 3 plugin to generate images from text and then use the IT support plugin to get support from the IT team.
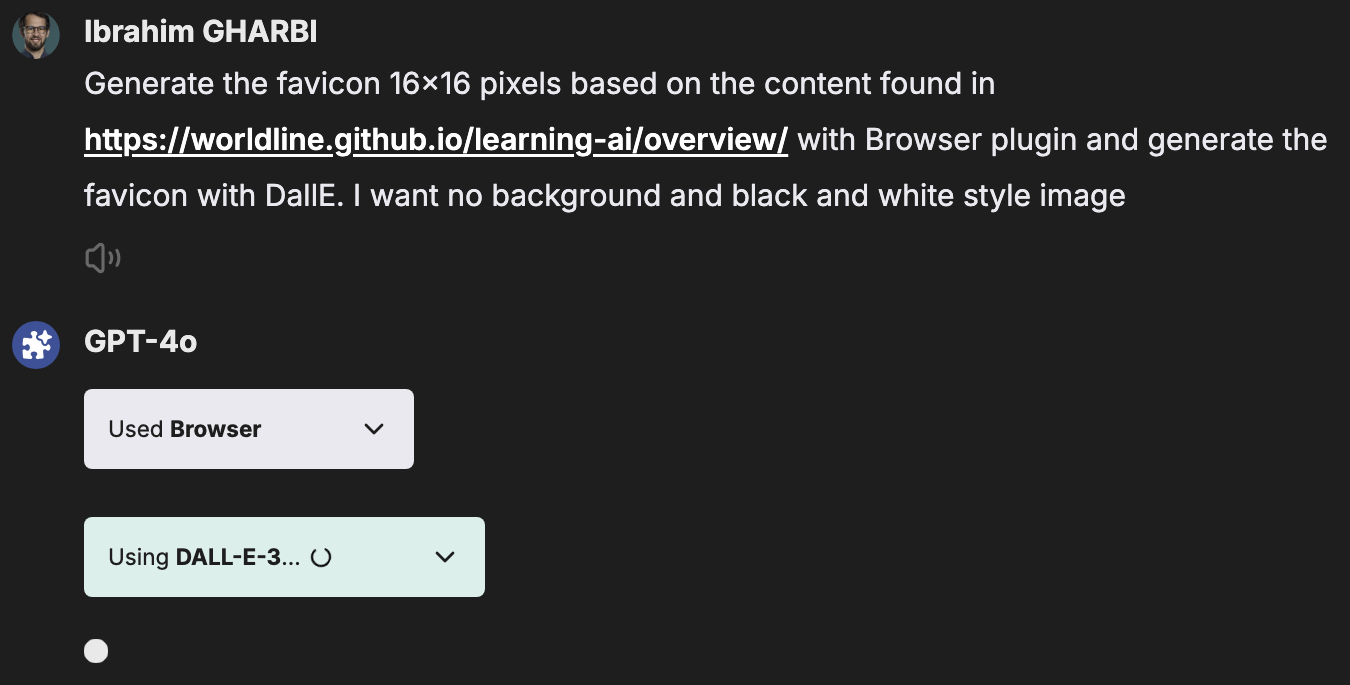
Generate the favicon 16x16 pixels based on the content found in
https://worldline.github.io/learning-ai/overview/ with Browser plugin
and generate the favicon with DallE. I want no background and black and white image

RAG
RAG is possible with LibreChat. You can use RAG to create a conversation with the AI. To can add files to the conversation, you go to the file tab and select the file you want to add. Then the file will be added to the file manager and you can use it in the prompt.
The file can be an png, a video, a text file, or a PDF file.
🧪 Exercises
1. Prompt creation
Select one prompt engineering technique and make a prompt in librechat that can be called with the /[prompt_name] command.
2. Plugins mixing
Use the Browse and Dall-E plugins to create a prompt that generates a a favicon based on the content of this learning-ai website.
3. Make your own assistant
Choose your favorite topic ( cooking, travel, sports, etc.) and create an assistant that can answer questions about it. You can share documents, files and instructions to configure your custom assistant and use it.
Offline (LM Studio)
Disclamer
Be careful with offline prompting models downloaded from the internet. They can contain malicious code. And also the size of the model can be very large from few Gb to few Tb.
Definitions
If you don't want to use the online AI providers, you can use offline prompting. This technique involves using a local LLM to generate responses to prompts. It is useful for developers who want to use a local LLM for offline prompting or for those who want to experiment with different LLMs without relying on online providers.
LM Studio is a tool that allows developers to experiment with different LLMs without relying on online providers. It provides a user-friendly interface for selecting and configuring LLMs, as well as a chat interface for interacting with the LLMs. It also includes features for fine-tuning and deploying LLMs. This technique is useful for developers who want to experiment with different LLMs.
Installation
For installation, you can follow the instructions here
Model configuration
You can configure the model you want to use in the settings tab. You can select the model you want to use and configure it according to your needs.
Context Length: The context length is the number of tokens that will be used as context for the model. This is important because it determines how much information the model can use to generate a response. A longer context length will allow the model to generate more detailed and relevant responses, but it may also increase the computational cost of the model.
GPU Offload: This option allows you to offload the model to a GPU if available. This can significantly speed up the generation process, especially for longer prompts or complex models.
CPU Threads: This option allows you to specify the number of CPU threads to use for the model. This can be useful for controlling the computational resources used by the model.
Evaluation batch size: This option allows you to specify the batch size for evaluation. This is important for evaluating the performance of the model and can affect the speed and accuracy of the generation process.
RoPE Frequency base: The Rotary Position Embeddings is a technique used to improve the performance of transformer-based models. This is important for controlling the output length of the model and can affect the quality of the generated responses.
Keep model in memory: This option allows you to keep the model in memory after the generation process is complete. This can be useful for generating multiple responses or for using the model for offline prompting.
Try mmap() for faster loading: This option allows you to try using mmap() for faster loading of the model. This can be useful for loading large models or for generating responses quickly.
Seed: This option allows you to specify a seed for the model. This can be useful for controlling the randomness of the generated responses.
Flash Attention: This option allows you to enable flash attention for the model. This can be useful for generating more detailed and accurate responses, but it may also increase the computational cost of the model.
enable APIs
You can use the APIs to generate responses from the models. To enable the API server with LM Studio, you need to set the API Server option to ON in the settings tab. You can then use the API endpoints to generate responses from the models.
2024-11-15 18:45:22 [INFO] [LM STUDIO SERVER] Success! HTTP server listening on port 1234
2024-11-15 18:45:22 [INFO]
2024-11-15 18:45:22 [INFO] [LM STUDIO SERVER] Supported endpoints:
2024-11-15 18:45:22 [INFO] [LM STUDIO SERVER] -> GET http://localhost:1234/v1/models
2024-11-15 18:45:22 [INFO] [LM STUDIO SERVER] -> POST http://localhost:1234/v1/chat/completions
2024-11-15 18:45:22 [INFO] [LM STUDIO SERVER] -> POST http://localhost:1234/v1/completions
2024-11-15 18:45:22 [INFO] [LM STUDIO SERVER] -> POST http://localhost:1234/v1/embeddings
2024-11-15 18:45:22 [INFO]
2024-11-15 18:45:22 [INFO] [LM STUDIO SERVER] Logs are saved into /Users/ibrahim/.cache/lm-studio/server-logs
2024-11-15 18:45:22 [INFO] Server started.
2024-11-15 18:45:22 [INFO] Just-in-time model loading active.
You can use the endpoints to generate responses from the models. The endpoints are as follows:
GET /v1/models: This endpoint returns a list of the available models.POST /v1/chat/completions: This endpoint generates responses from the models using the chat format.Chat format is used for tasks such as chatbots, conversational AI, and language learning.POST /v1/completions: This endpoint generates responses from the models using the completion format. Completion format is used for tasks such as question answering, summarization, and text generation.POST /v1/embeddings: This endpoint generates embeddings from the models. Embeddings are used for tasks such as sentiment analysis, text classification, and language translation.
🧪 Exercises
- Install LM Studio and configure the model you want to use.
- Enable the API server and test the endpoints using curl or Postman.